This blog is a continuation of my previous blog introducing the basic concepts of machine learning. We’ll use the same ideas here with little modification to work with more general algorithms. The previous blog was about backpropagation and gradient descent.
In the previous blog we used a linear function to model the relationship between the input and output, this only worked because the data was a linear function (). However, this cannot work for more complex functions, such as polynomials, images, etc. The linear function we used to model our data was a single neuron (or a perceptron).
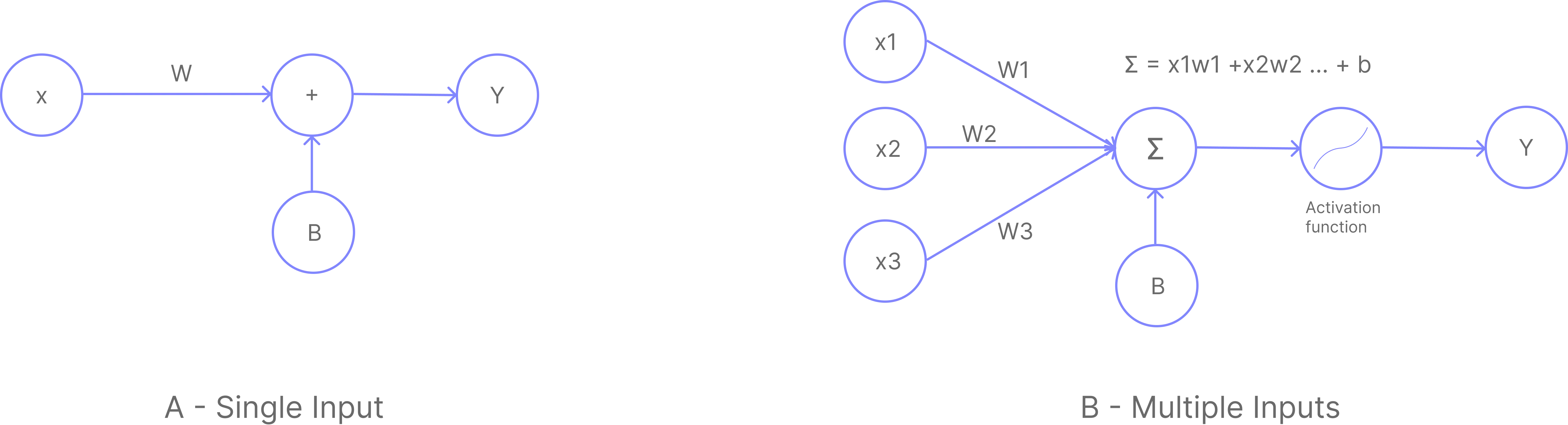
A- Single Input Neuron:
B- Multi Input Neuron:
Think of a single neuron as one linear equation. On its own it can only draw a straight line through data. To model something more complex, we need many of these equations working together. That is exactly what a neural network does: it stacks multiple neurons so that each one handles a piece of the problem, and together they can represent far richer relationships.
With this basic building block, we can create more complex functions by stacking multiple neurons together. This is called a neural network. The network can be represented as a graph of neurons, where each neuron is a node and the connections between neurons are the edges. They can also be stacked in layers, where each layer is a group of neurons that are connected to other neurons in the previous and/or next layers.
A and B are the same thing, just with different number of inputs. They can also be referred to as a single layer neural network.
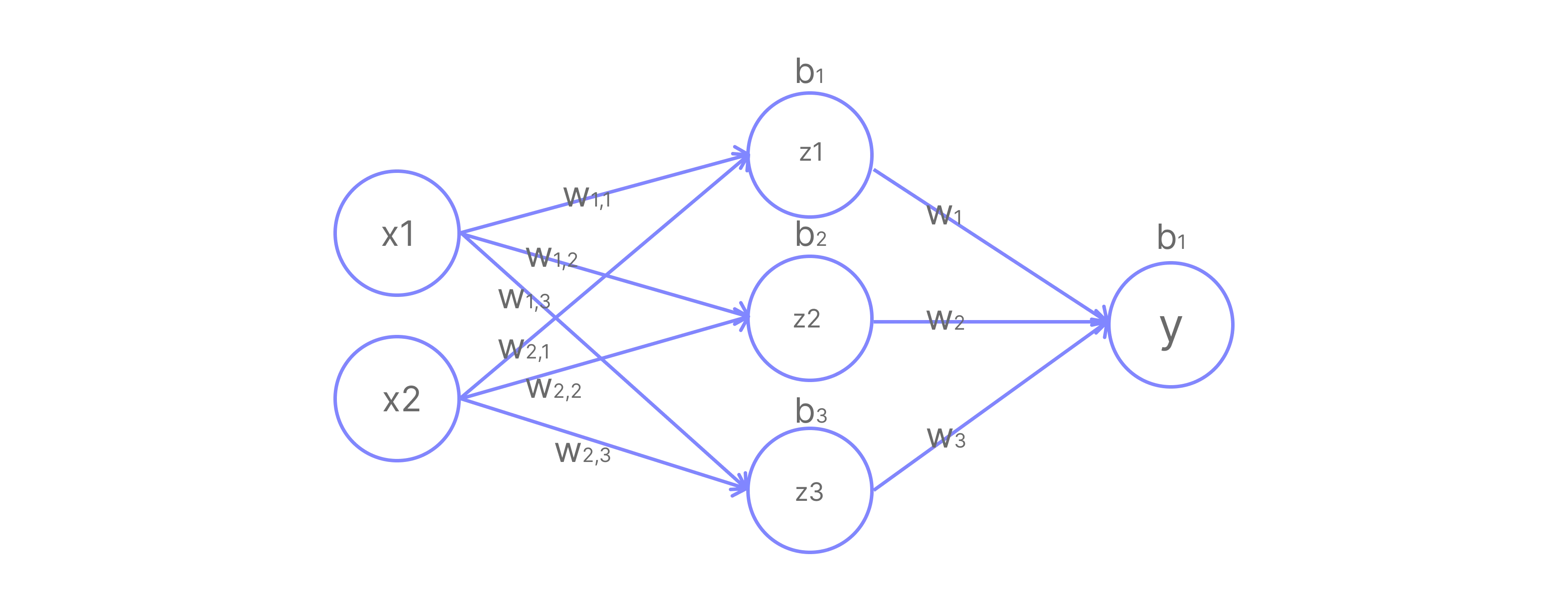
In the image above, we have a neural network with 2 input neurons, 3 hidden neurons, and 1 output neuron. The hidden layer is the layer between the input and output layers. The output layer is the layer that produces the final output .
Let’s digest the image above. We have 2 input neurons, and . They are connected to 3 hidden neurons, , , and . Each hidden neuron is connected to both input neurons and has its own weights and bias:
- : weights and bias
- : weights and bias
- : weights and bias
We can write the equations for the hidden layer as:
Writing all three equations at once in matrix form:
This is the same idea as , just extended to matrices. The dimensions work out as: is , is , so gives a result, which we then add the bias to.
For the output layer, we have 3 inputs connecting to 1 output neuron , with weights and bias :
In matrix form:
Activation Functions
Even after stacking multiple layers, our model is fundamentally still a linear function. Substituting the hidden layer into the output layer:
The whole network collapses into , just another linear function. No matter how many layers we stack, without something extra, it always reduces to a single linear transformation.
To model non-linear problems like image recognition or complex curve fitting, we must introduce non-linearity. This is the role of Activation Functions.
An activation function is applied to each neuron’s output before passing it to the next layer, breaking the collapse and giving the network the ability to learn complex patterns.
The most common activation functions are:
-
Sigmoid: Squeezes output to the range . Used in the output layer for binary classification.
-
ReLU (Rectified Linear Unit): Passes positive values unchanged, zeros out negatives. The most popular choice for hidden layers.
-
Tanh (Hyperbolic Tangent): Squeezes output to the range . Similar to sigmoid but zero-centered.
Applying activation function to the hidden layer output:
The full network equation becomes:
Because is non-linear, this can no longer collapse into a single . The network can now approximate practically any continuous function.
NOTE: This network can approximate a function of the form where is an arbitrary function.
Training the Network
We’ll use ReLU as our activation function and train via backpropagation and gradient descent. Throughout this section, refers to the network’s prediction and refers to the true target value we want the network to learn. There are four steps:
- Forward Pass run inputs through the network to get a prediction
- Calculate Loss measure how wrong the prediction is
- Backward Pass compute gradients of the loss w.r.t. each weight
- Update Weights nudge weights in the direction that reduces the loss
Step 1 Forward Pass
Given data:
Network equations:
This is function composition:
Parameters:
is because we have 3 hidden neurons each receiving 2 inputs. Also note that the parameters are initialized randomly.
Computing the hidden layer first apply the weights, then ReLU:
becomes 0 because its pre-activation was negative, so this neuron contributes nothing to the output.
Computing the output:
Step 2 Calculate Loss
We use Mean Squared Error (MSE) to measure how far our prediction () is from the target ():
With a single sample ():
Step 3 Backward Pass
We work backwards through the network, computing how much each weight contributed to the loss.
The chain rule lets us do this by multiplying together a chain of small derivatives, one per layer. Before we apply it, we first compute each individual piece we will need.
Gradient of the loss w.r.t. the prediction :
Before we can apply the chain rule, we need a few individual partial derivatives first, think of them as the building blocks that will be multiplied together in the next section.
Output layer gradients from :
Since , differentiating w.r.t. gives , not itself. The gradient scales with what the weights received as input, not their current values.
Hidden layer gradients from :
The ReLU derivative acts as a gate: it passes the gradient through where the neuron was active, and blocks it where the neuron was inactive.
For our pre-activations , the gate values are:
The gradient w.r.t. and (before the ReLU):
Chain Rule
Combining the above using the chain rule:
For the hidden layer, the gradient must also pass through the ReLU gate:
Because ‘s pre-activation was , its ReLU gate is 0, so no gradient flows back to the third row of . Those weights receive no update at all for this sample. This is known as the “dying ReLU” problem.
Step 4: Update Weights
With Gradient Descent, we update each parameter by subtracting a fraction of its gradient, controlled by the learning rate :
With :
Our network now becomes:
After one update, the network is slightly better at predicting 3 for input . Repeating this many times across many samples gradually trains the network to map inputs to correct outputs.
Automating the Process
Let’s write some code to help us train the model quickly instead of doing it by hand. I will use numpy to make it easy for beginners to understand, but you can go ahead and implement it in your favorite framework, either pytorch or tensorflow.
import numpy as np
# Initialize weights and biases
# we used random values in the previous blog
W_in = np.array([[1, 2],
[-3, 4],
[1, -1]])
b_in = np.array([1, 2, 0])
W_out = np.array([[1, 2, 3]])
b_out = 1
# Input and target
x = np.array([1, 2])
y_target = 3
learning_rate = 0.01
# Training Loop
for epoch in range(10):
# Forward pass
u = np.dot(W_in, x) + b_in
z = np.maximum(0, u)
y = np.dot(W_out, z) + b_out
# Calculate Loss
loss = 0.5 * (y - y_target)**2
# Backward Pass
dL_dy = (y - y_target)
# Output layer gradients
dL_dW_out = np.outer(dL_dy, z)
dL_db_out = dL_dy
# Hidden layer gradients
dL_dz = np.dot(dL_dy.reshape(-1, 1), W_out)
dL_du = dL_dz * (u > 0)
dL_dW_in = np.dot(dL_du.T, x.reshape(1, -1))
dL_db_in = dL_du.flatten()
# Update parameters
W_in = W_in - learning_rate * dL_dW_in
b_in = b_in - learning_rate * dL_db_in
W_out = W_out - learning_rate * dL_dW_out
b_out = b_out - learning_rate * dL_db_out
print(f"Epoch {epoch}: Loss = {loss[0]:.4f}, Prediction = {y[0]:.4f}")Epoch 0: Loss = 162.0000, Prediction = 21.0000
Epoch 1: Loss = 0.5080, Prediction = 4.0080
Epoch 2: Loss = 0.1182, Prediction = 3.4862
Epoch 3: Loss = 0.0282, Prediction = 3.2376
Epoch 4: Loss = 0.0068, Prediction = 3.1167
Epoch 5: Loss = 0.0017, Prediction = 3.0575
Epoch 6: Loss = 0.0004, Prediction = 3.0283
Epoch 7: Loss = 0.0001, Prediction = 3.0140
Epoch 8: Loss = 0.0000, Prediction = 3.0069
Epoch 9: Loss = 0.0000, Prediction = 3.0034We have seen a complex network evolve to learn the function that maps to . This kind of network is called a Multi-Layer Perceptron (MLP) or Feed Forward Neural Network (FFNN). The general formula for any MLP is:
Reading this from the inside out: is the first layer, it takes the raw input and applies . Then applies the activation function. The result is fed into , which does the same thing, and so on up to layer , the output layer. Each subscript (1, 2, …, ) just labels which layer we are on. Our worked example had : one hidden layer and one output layer.
NOTE: You can use any activation function you want, usually based on the problem you are solving.
Summary
Here is everything we covered in this blog:
Neural Networks are built by stacking multiple neurons into layers. Each layer applies a linear transformation , where is a weight matrix and is a bias vector. The number of rows in equals the number of neurons in that layer, and the number of columns equals the number of inputs it receives.
Activation Functions like ReLU, Sigmoid, and Tanh introduce non-linearity between layers. Without them, the entire network collapses into a single linear function regardless of how many layers are stacked.
Forward Pass computes the prediction by passing the input through each layer in sequence: multiply by weights, add bias, apply activation, and repeat until the output layer.
Loss Function measures how wrong the prediction is. We used Mean Squared Error:
Backward Pass applies the chain rule to compute the gradient of the loss with respect to every weight and bias, working from the output layer back to the input. The ReLU derivative acts as a gate, passing gradients through active neurons and blocking them for inactive ones (pre-activation ). A neuron that is blocked receives no weight update for that sample, which is called the dying ReLU problem.
Gradient Descent updates each parameter by stepping in the direction that reduces the loss:
MLP (Multi-Layer Perceptron) is the general name for this architecture. Its formula is:
where and is any activation function.
Repeating these four steps over many samples and many epochs gradually drives the loss toward zero, teaching the network to correctly map inputs to outputs.